🔭 Exploration de données#
Datasette a été initialement conçu comme une application d'exploration et d'analyse de données pour le journalisme. Les deux manières majeures d'effectuer ces tâches se font au travers de l'interface web et de l'interpréteur SQL.
Interface Web#
Sans taper une ligne de code SQL, nous pouvons commencer nos explorations directement avec l'interface web de Datasette, un peu à la manière d'un tableur.
Tri#
Pour trier les données d'une table selon une colonne, nous pouvons accéder au menu contextuel de colonne (en forme d'engrenage ⚙️) et sélectionner "Sort ascending" (tri croissant) ou "Sort descending" (tri décroissant) :
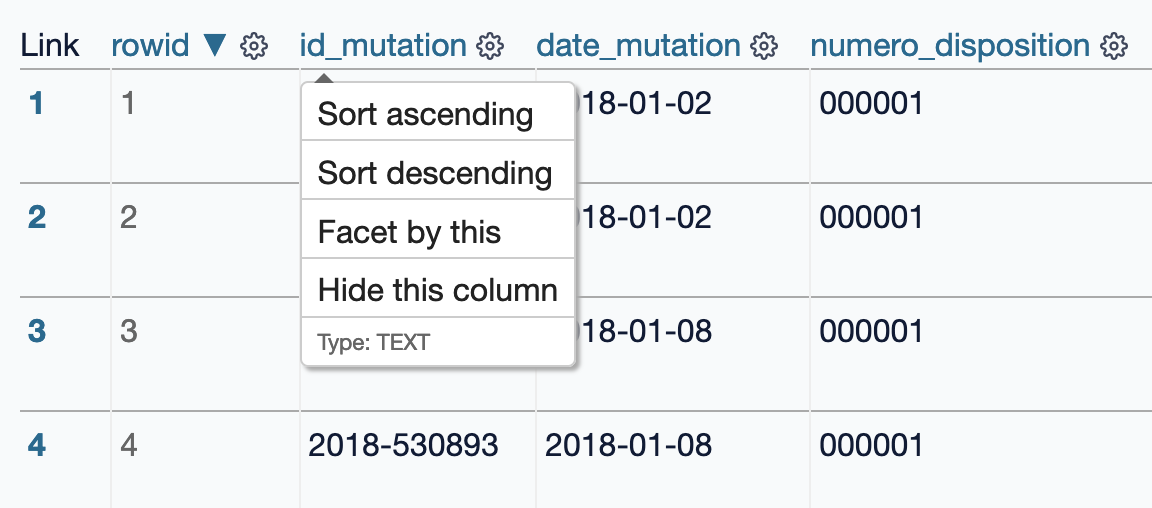
Il est également possible de cliquer directement sur le nom d'une colonne : une fois pour un tri croissant, deux fois pour un tri décroissant.
Filtrage#
Pour trier les données d'une table, il est possible d'utiliser le formulaire de filtres :
- Sélectionner la colonne
- Sélectionner l'opérateur de comparaison
- Taper la valeur
- Cliquer sur "Apply"
Par exemple, pour filtrer les DVF uniquement sur les ventes d'appartements à Grenoble :
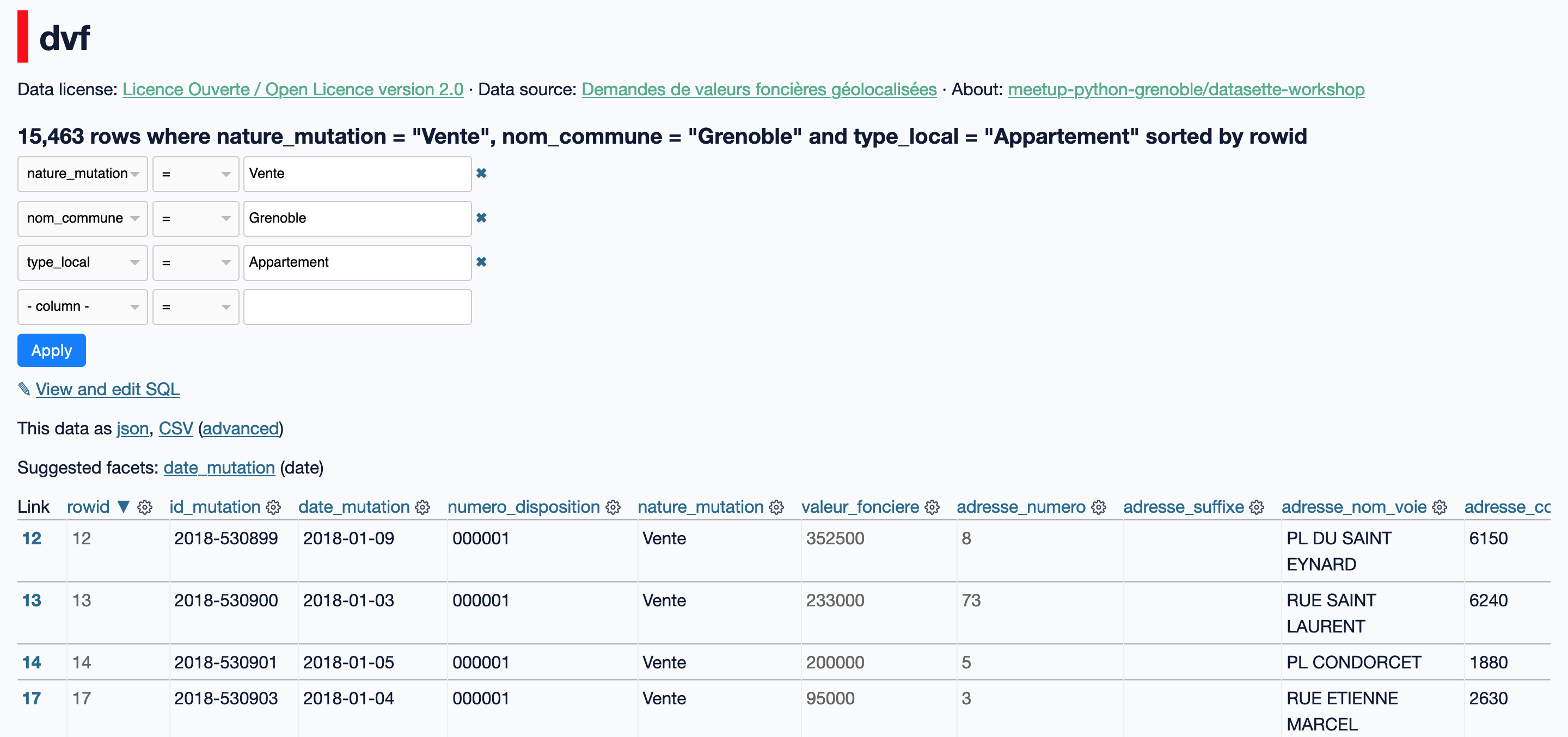
Vous pouvez combiner autant de filtres désirés, et l'utilisation judicieuse de tous les opérateurs de comparaison disponibles permet généralement d'accéder au sous-ensemble de données recherchées.
Facettes#
Datasette permet également d'explorer les données avec une recherche à facettes permettant d'augmenter l'interface web avec des critères de sélection basés sur les valeurs de colonnes.
Pour analyser une colonne avec une facette, cliquer sur le menu contextuel (⚙️) puis sélectionner "Facet by this" :
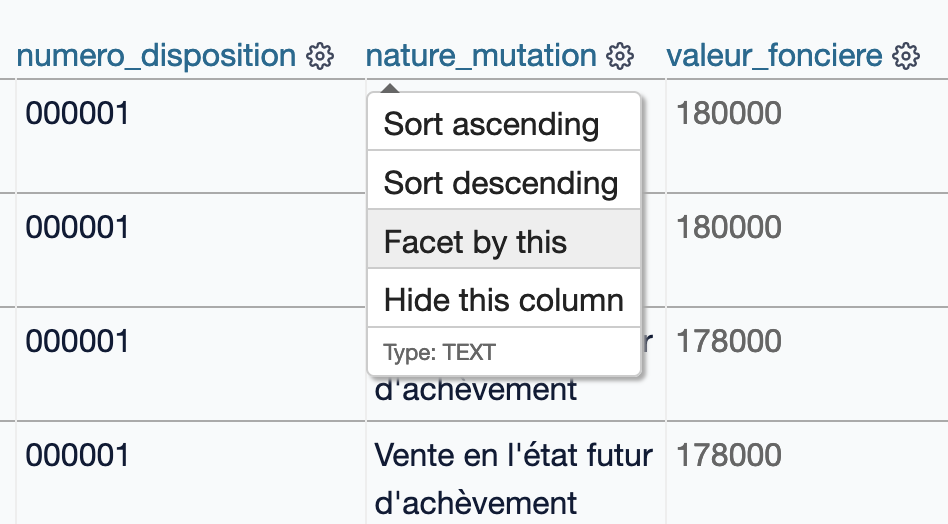
Par exemple, en sélectionnant des facettes pour le type de mutation et du type de local, nous obtenons une analyse des DVF avec le nombre de lignes pour chaque valeur correspondante :
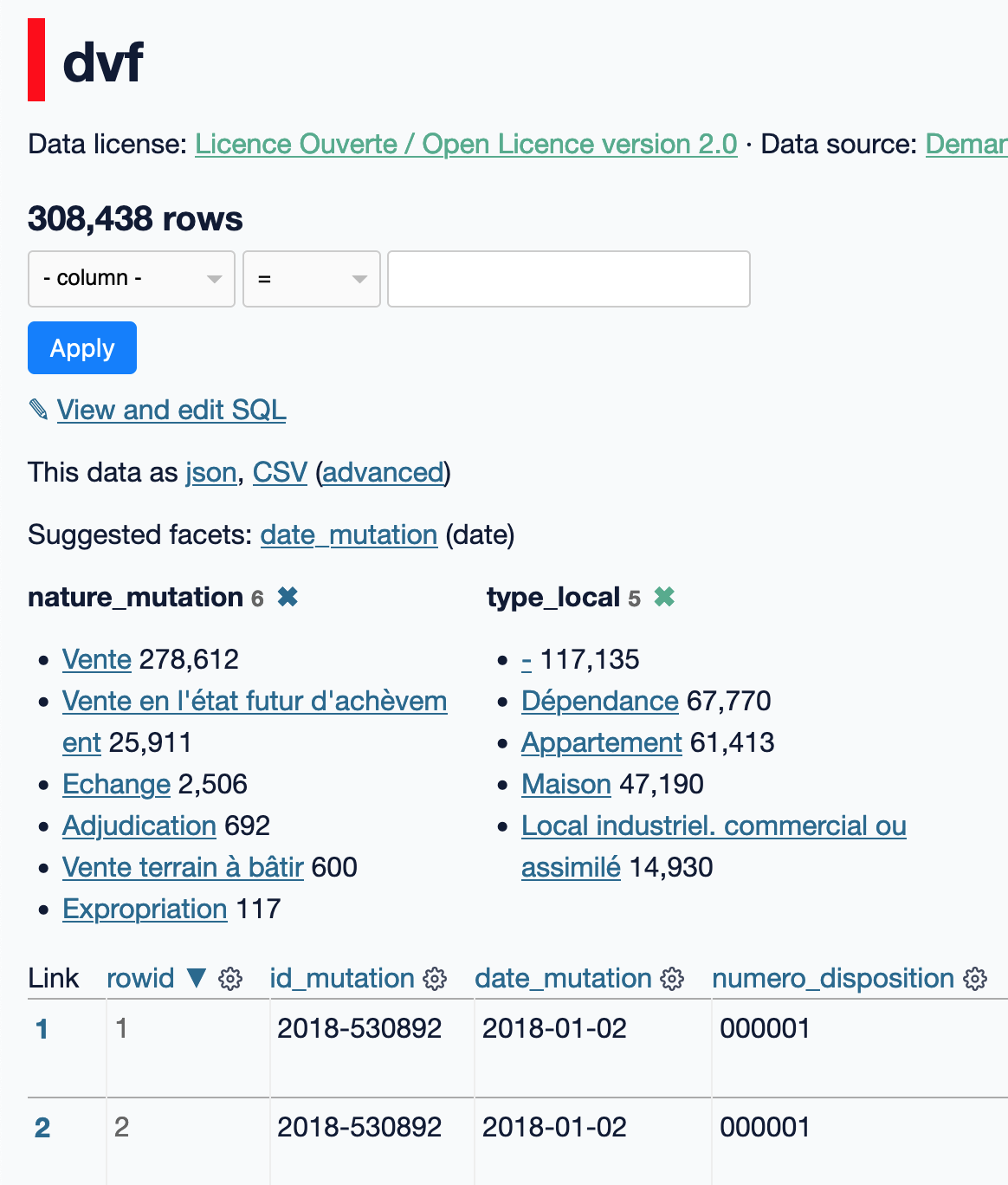
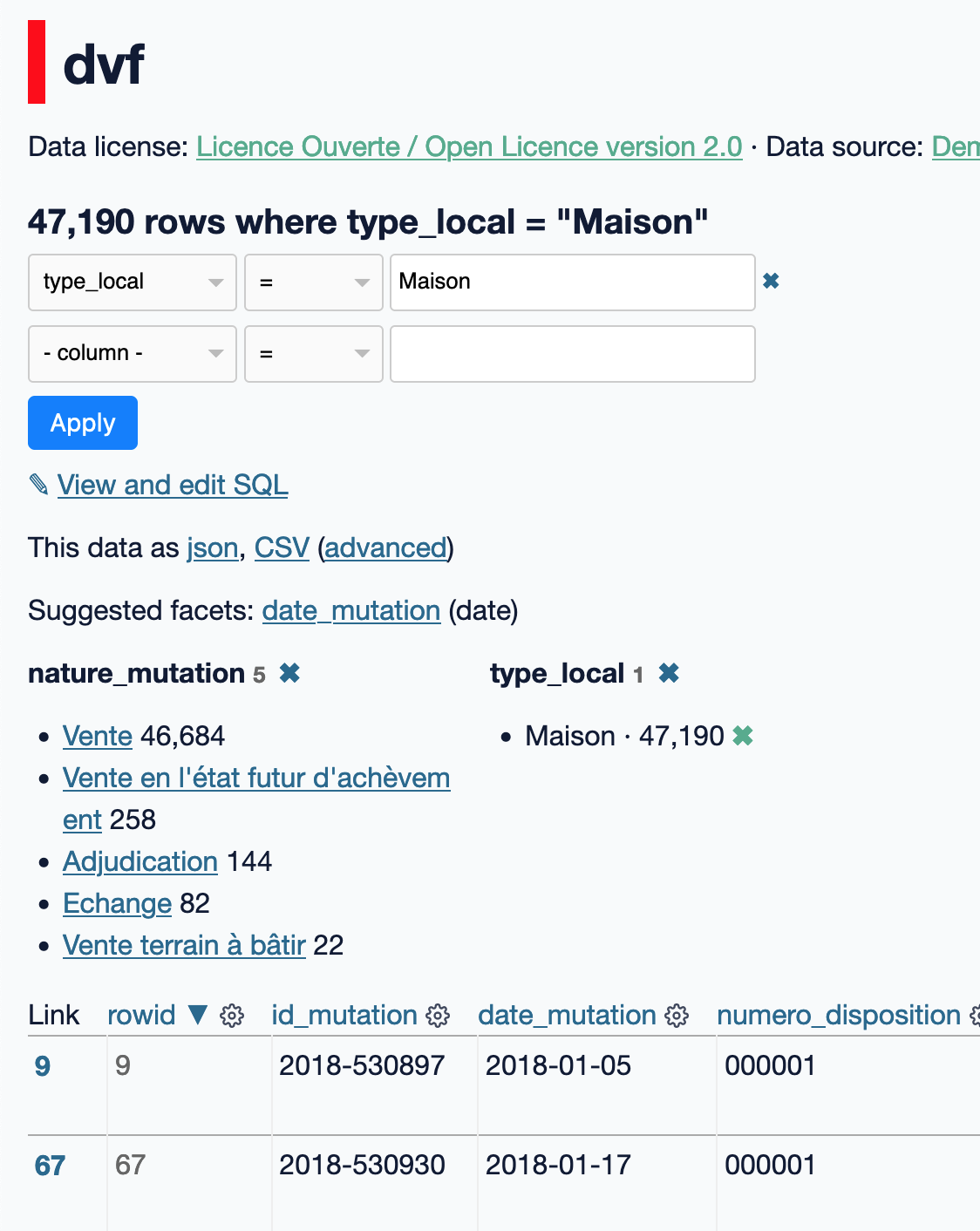
Lorsque les facettes sont affichées, il est possible de cliquer une sur valeur pour déclencher un filtre des données. Par exemple, en cliquant sur le type de local "Maison", nous obtenons la vue suivante (remarquez la mise à jour des valeurs pour la facette de nature de mutation) :
SQL#
Lorsque l'interface web de Datasette ne suffit plus pour analyser ou extraire les données souhaitées, il possible d'utiliser des requêtes SQL directement.
Pour accéder à l'interpréteur SQL, il est possible de continuer une recherche depuis l'interface puis de cliquer sur "View and edit SQL" :
ou bien de passer la vue de la base de données :
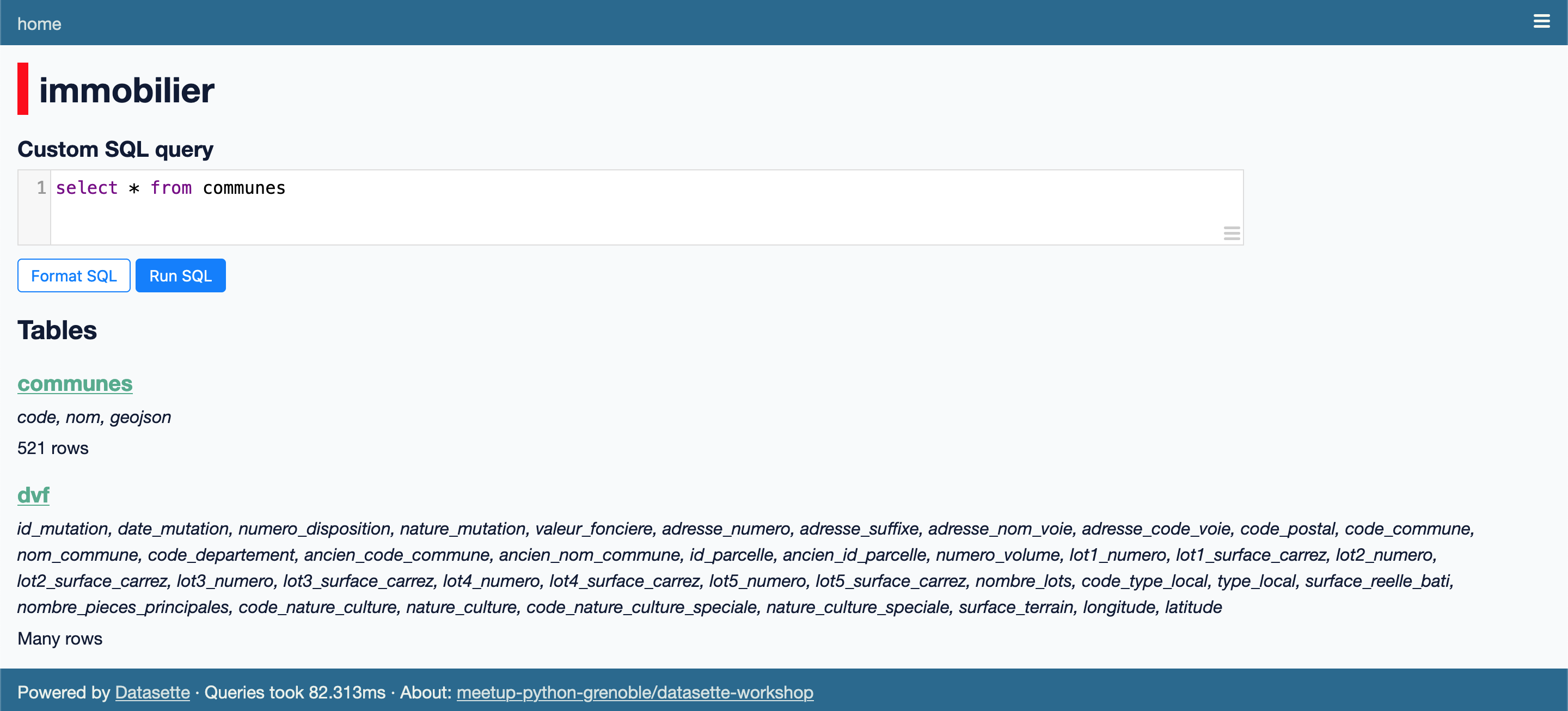
Dans les deux cas, nous obtenons un éditeur de requêtes SQL, avec affichage du résultat de la requête courante :

Toutes les fonctionnalités SQL supportées par SQLite sont ainsi disponibles dans Datasette :
- Fonctions scalaires :
abs,lower,random, etc. - Fonctions d'agrégations :
count,sum,avg, etc. - Fonctions de fenêtrage :
row_number,rank, etc. - Fonctions de date et temps :
date,time,strftime, etc. - Fonctions mathématiques :
ceil,floor,sin,cos, etc. - Fonctions et opérateurs JSON :
json_extract,json_array,json_object,->,->>, etc. - Jointures :
INNER JOIN,LEFT JOIN,CROSS JOIN, etc. - CTE :
WITH ... AS, etc.
Il est également possible d'utiliser des extensions SQLite natives (ex : SpatiaLite) ainsi que de définir des fonctions SQL personnalisées.
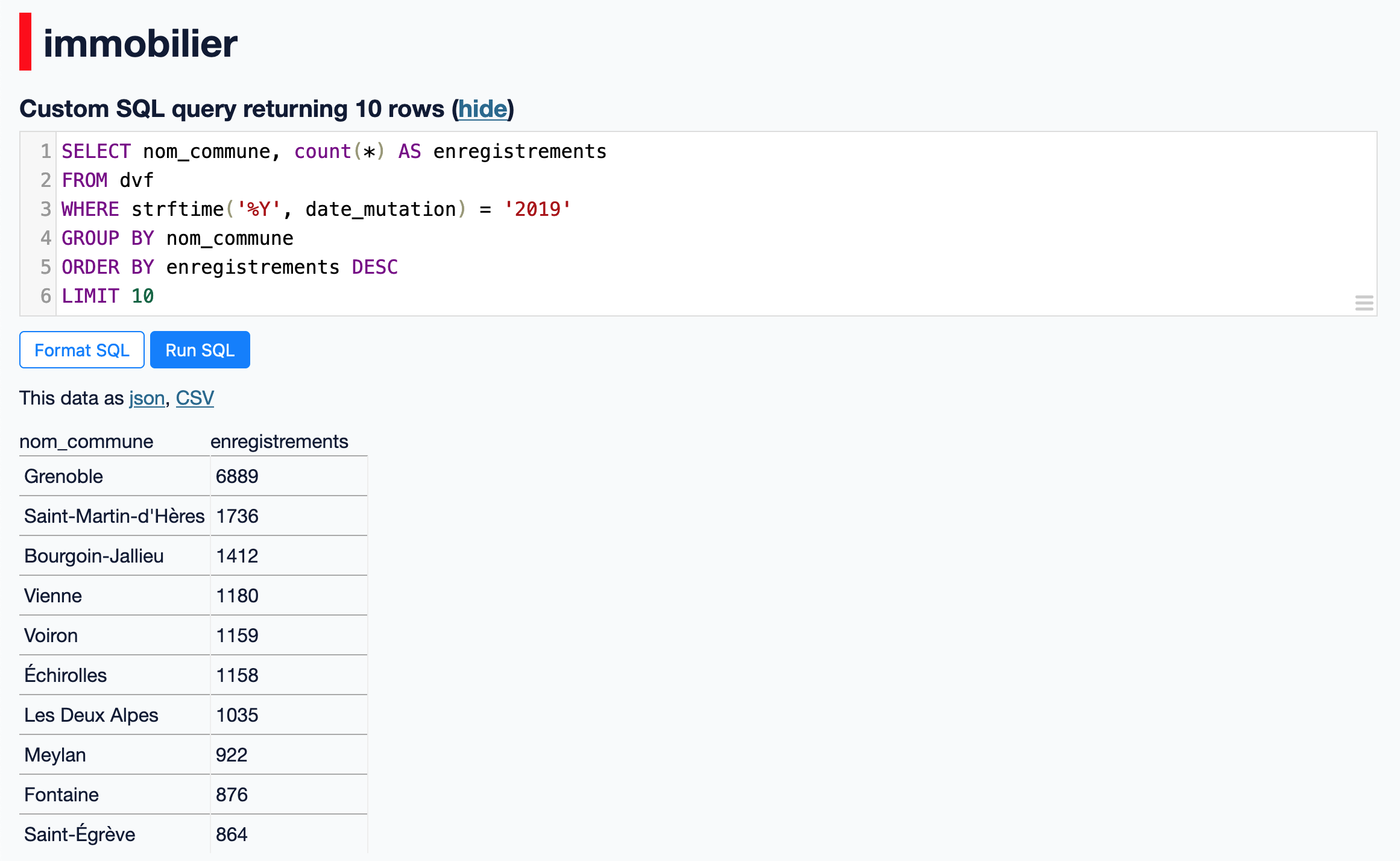
Par exemple, pour obtenir les dix communes avec le plus grand nombre d'enregistrements sur l'année 2019 nous pouvons utiliser la requête SQL suivante :
SELECT nom_commune, count(*) AS enregistrements
FROM dvf
WHERE strftime('%Y', date_mutation) = '2019'
GROUP BY nom_commune
ORDER BY enregistrements DESC
LIMIT 10
En tapant cette requête SQL dans l'éditeur de Datasette, nous obtenons les données suivantes :
Export#
Dès lors que les données recherchées ont été obtenus (que ce soit via l'interface web et/ou par requête SQL), il est possible d'exporter les données au format CSV ou JSON en cliquant sur un des liens mentionné comme "This data as json, CSV".
Des plugins permettent d'ajouter des formats d'exports additionnels.
Déploiement#
Enfin, un des objectifs du projet Datasette est la publication de données. Nous ne couvrirons pas cet aspect dans cet atelier mais sachez qu'il est très simple de déployer une instance de Datasette embarquant une ou plusieurs bases de données SQLite sur un hébergement moderne de type serverless (Google Cloud Run, Vercel, Fly.io, Heroku, etc.).